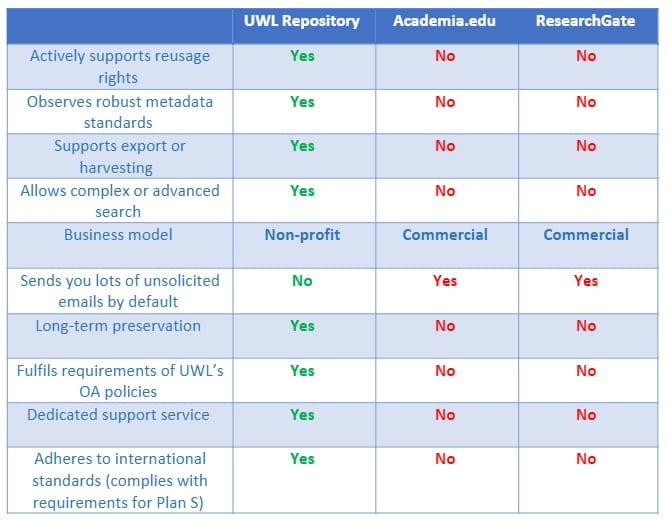
ORCID (Open Researcher and Contributor Identifier) is a an international, not-for-profit organisation that provides a registry of unique identifiers for researchers and scholars that is open, non-proprietary and transparent. These are also increasingly used by research organisations, funders, and publishers.
ORICD is a unique and persistent digital identifier used to disambiguate researchers from one another (especially those with similar names). It also allows a researcher’s work to be properly identified if their name changes later in their career, for example if they take on a partner’s surname in marriage or change their name to reflect their gender identity. ORCID author IDs also provide clarity where different naming conventions are used, or where middle initials can be applied in a variety of ways across publications.
This is important for bibliographic databases (such as SCOPUS, Web of Science, and PubMed), as well as the UWL Repository, as it will help to ensure you get the credit for the research you produce. ORCIDs are also mandated by a growing range of funders and publishers, including: NIHR, Wellcome Trust, PLOS, eLife, IEEE, Science, Wiley, Hindawi, JMIR and Frontiers.
One of the major benefits of the identifier is that it supports authentication across multiple platforms allowing researchers to link their professional activities and publications to their unique record; ensuring their scholarly contributions are properly attributed and permanently showcased.
ORCID at UWL
All UWL researchers should sign-up for and use ORCIDs as required by paragraph 14.2 of the UWL Publications Policy which states that:
All authors should register with the ORCID author ID service in order to facilitate future linking of outputs to authors and citations to ensure audit compliance.
ORCID registration is free and takes a matter of seconds.
Register or connect your ORCID to the UWL Repository
You may register for an ORCID identifier at http://www.orcid.org. Registration is free and fast: you need only enter your name and email address and create a password.
Alternatively you can register by clicking on the Manage ORCID Permission tab once logged into UWL Repository. From here you can click on the “Create or Connect your ORCID ID” button.
If you already have an iD, please also click on the Manage ORCID Permission tab once logged into UWL Repository and then the “Create or Connect your ORCID iD” button. Once you have granted permissions for reading and writing between ORCID and the UWL Repository, you will have two new buttons in your Manage deposits area, “Import from orcid.org” and “Export to orcid.org”. These allow you to push and pull descriptive records between UWL Repository and ORCID.
ResearchGate and Academia.edu are known as academic social networking sites (ASNS). Their stated aims are to connect researchers with common interests based on their institutional affiliation and the type of research content they make available online. However, as commercial entities, they offer a service at no initial cost to the consumer as a way of establishing a foundation for future transactions including offering premium features to fee paying members (such as extra analytics or advanced search) or advertising space for companies and other organisations.
In 2016 for example, Academia.edu trialled a service which would enable authors to pay for their work to receive a ‘recommended’ status in addition to disclosing readers’ ranks (Bond, 2017, paras. 5 & 6, cited in Makula, 2017).
UWL Repository
The UWL Repository is a non-commercial digital archive of research and scholarship maintained by the University of West London library service, enabling authors to showcase a version of their output (usually in the form of an author manuscript) for the benefit of anybody with an Internet connection. The primary aims of the UWL Repository are to make these outputs as widely available as possible (with limited restrictions over reuse) and to ensure their long-term preservation. These conditions also allow staff members at UWL to comply easily with national, institutional and funder mandates..
Key Differences
1. Open access
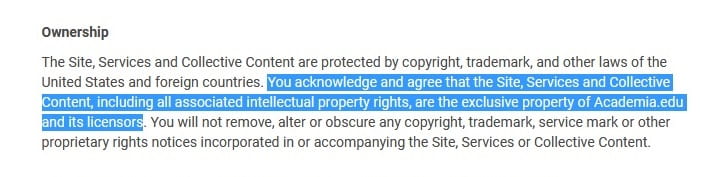
While Academia.edu and ResearchGate encourage users to upload content to their respective platforms in order to make them publicly accessible, they do so bydeclaring ownership of the content they receive (upon accepting the terms of use on registration*).
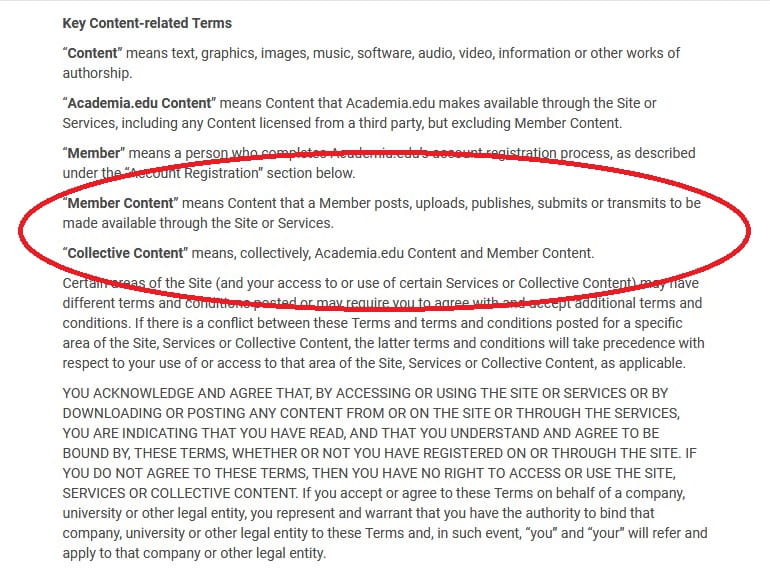
Ownership (Academia.edu: Terms of Service). Screengrab taken in October 2019.* Academia.edu for example refers to this as ‘collective content’ in their Terms of Service.
In order to protect these interests, they are obliged to distance themselves from openly supporting re-usage rights and actively prohibit the use of robots, crawlers, and data mining tools.
Furthermore, lack of clear guidance on self-archiving on both websites (in addition to general misconceptions around open access) has resulted in users routinely infringing copyright or breaching publisher agreements as well as journal policies on embargos. In 2013 for example, Elsevier sent almost 3000 DMCA takedown notices to Academia.edu on account of what it claimed to be unauthorised sharing of the publishing giant’s content (Hall, 2015).
The UWL Repository on the other hand is an extension of the research and scholarly communication support provided by the library and is committed to openness as defined by the Budapest Open Access Initiative (BOAI). In addition to access for example, the UWL Repositoryrecognises the importance of the availability of research and scholarship under conditions which permit users to read, download, copy, distribute, print, search, or link to the full texts of articles, crawl them for indexing, pass them as data to software, or use them for any other lawful purpose. Moreover, in situations where access to the full text of an output on the repository is restricted (this is sometimes the case with monographs and book chapters or where content is generally subject to an embargo,) anyone may access the metadata free of charge.
2. Discoverability
Many have observed that the majority of works posted toacademic social networking sites lack robust metadata and that upload interfaces are geared towards enriching proprietary content rather than towards promoting the sharing of correct and complete scientific information (Dingemanse, 2016). As a result academic social networking sitesoften fall short of complying with minimum guidelines for metadata exposure of indexing services such asGoogle Scholar which affect search rankings and overall researchfindability.Up until recently, Academia.edu for example did not provide a field for digital object identifiers (DOI) and still does not allow PMID codes or links which direct users to sources outside of their platform.
One important way in which the UWL Repository optimizes discoverability of content is by using standardised records, based on established metadata schema. Thesemake it easier for web indexing services (like CORE and Google Scholar)that use “parsers” to identify bibliographic data, to recognise papers and improve their overall visibility.Unlike ASNSs, dedicated library staff are available to review and improvethemetadata on the UWL Repository, to increasethe discoverability of these author outputs. Moreover, integration with CORE services (which stands for COnnectedREpositories) allows repository users to benefit from a recommender feature which displays results for similar titles across other repositories, meaning that those users are not simply confined to one research or scholarly archive.
3. Interoperability
Hostility towards interoperability (standards which facilitate technical reciprocity between other products or systems) by Academia.edu and ResearchGate means that many preventable errors relating to paucity of bibliographic data and record duplication are never resolved. On Academia.edu and ResearchGate there is no way to import a record via a DOI or PMID code via the upload interface which would help to harmonise records and address version control. In instances where ResearchGate permits users to import publications from some applications, it provides no method for getting that same data out of the ResearchGate ecosystem (Fortney and Gonder, 2015).
According to the Confederation of Open Access Repositories (COAR):
A single scientific repository is of limited value, real benefits come from the ability to exchange data within a network … interoperability allows us to exploit today’s computational services, and generate new knowledge from repository content (COAR, n.d., cited in petrknoth, 2019).
In contrast to ACSNs, the UWL Repository, respects users’ personal data whilst being fully interoperable by design (this is thanks to the power of something called the Open Archives Initiative Protocol for Metadata Harvesting or OAI-PMH). This allows it to communicate with other systems and transfer information, metadata, and digital objects between those systems as a matter of course.
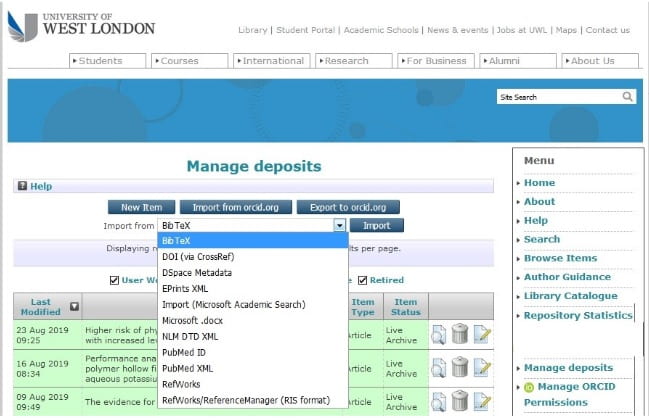
The screenshot below for instance, shows how easily researchers are able to pullexisting metadata records into the repository using a variety of sources including reference managers, scripts and unique identifiers.
The screenshot above, shows how easily researchers are able to pull existing metadata records into the repository using a variety of sources including reference managers, scripts and unique identifiers.
The UWL Repository also supports ORCiD (Open Researcher and Contributor ID) integration, allowing researchers to easily import and export records from the two systems, reduce duplication of effort and embed their unique persistent identifier within their submissions.
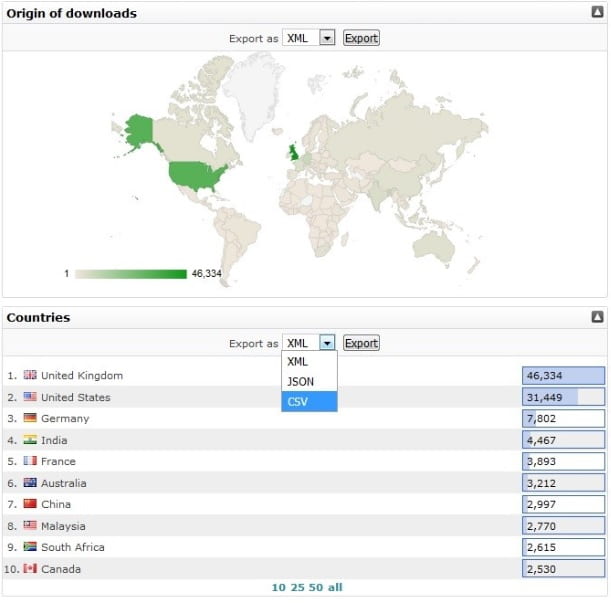
The statistics area also offers a range of options to customise repository data (by author, work, deposit, requests)and export the results as XML, JSON or CSV files, all without even logging in.
4. Searching
According to Makula (2017) ‘Academia.edu offers only the ability to browse by title, not subject, and a basic (not advanced) search mechanism that provides no guidance on how to conduct an effective inquiry’. Advanced searches are reserved most notably to premium account holders only.
Conversely, institutional archives such as the UWL Repository are adapted to support both browse and advanced search functionality depending on user preference. Users are invited tobrowse items by year, subject, academic school, author and item type as well as carry out simple andcomplex searchesusing faceted techniques and a range of category filterssuch as item type, publication status, journal titles, etc.
Burnett (2013) also points out that institutional and subject repositories have common standards for describing their contents which enable their metadata to be harvested by search engines and repository-specific search services. This capacity allowsusers to cross-search around3000 repositories worldwide with just one search query.
Just a few examples of such search services include:
BASE – from Bielefeld University Library,who provide more than 150 million items comprising a mixture ofboth “metadata-only” records (which contain no full–text) and actual full–text records.
CORE – from the Open University, who index about 11 millionrecords with extracted full–text, with content harvested mostly from repositories.
Unpaywall – from non-profit Impactstory, who harvest content from most journals as well as institutional repositories, with an index which currently hosts up to 20 million full-text and prioritises accuracy and precision (Burnett, 2013; Priem, 2019).
5. Business model
Both Academia.edu and ResearchGate are currently supported by venture capital funds. Although Academia.edu has a ‘dot.edu’ URL, it is not operated by a higher education institution or body. According to a blog post from University of California’s website, the domain name was registered before the rules that would now prohibit this use went into effect. On its filings with the Securities and Exchange Commission for instance it uses the legal name Academia Inc. (Fortney and Gonder, 2015).
Many commentators have ventured that the financial rationales of both Academia.edu and ResearchGate rest ultimately ‘on the ability to exploit the data flows generated by the academics who use the platform as an intermediary for sharing and discovering research’. Trending research data from academic social networking sites can then be repackaged to R&D institutions in a market which currently spends $800 billion on R&D in the private sector (including pharmaceuticals) globally (Hall, 2015).
6. Values and mission
Academic social networking sites have been widely criticised for attempting to recentralise disparate scholarly-led approaches to open access, in order to derive commercial value, particularly in the case of user-driven data. They are perceived by some to perpetuate individualistic practices which are in tension with the ethos of earlier community-orientated open access movements and consequently reproduce many of the problems associated with the pressure to demonstrate impact within the confines of legacy publishing. (Dingemanse, 2016; Hall, 2015). The ‘RG score’, a proprietary algorithm developed by ResearchGate is for instance reported to reach high values under highly questionable circumstances (Jordan, 2015; Murray, 2014).
The fleet of analytics conceived by academic social networking sites increasingly normalise surveillance. Academia.edu have perfected this with their increasingly intrusive notifications (“Someone in Sheffield, United Kingdom, mentioned you”) and ResearchGate have recently acquired a US patent for “Enhanced Online User-Interaction Tracking and Document Rendition” (Price, 2020). Both also promote social ranking over potentially meaningfulengagement in a way that ‘plays to our vanity [with] elements of its design [being] built to satisfy and amplify our craving for external validation’ (Dingemanse, 2016).
This is sustained by a campaign of aggressive emailing designed to incite users to engage with the platform further, oftenon the basis of fairly mundane activity.
A 2014 Nature report also revealed that a proportion of the profiles on the site are not maintained by real people, but are automatically generated – though usually incompletely and with little regard to the individual. This understandably annoys researchers who do not want to interact with the site but who then feel pressured to engage because the page misrepresents them.
Institutional and subject repositories, by contrast, focus on balancing support for open access to research and scholarship for the public good with the needs to meet conditions for future research funding.The University of California observes that ‘open access repositories are usually managed by universities, government agencies, or non–profit associations. Affiliation with a larger institution (that has a public service mission)freesrepositories from shareholder pressuresmeaning they are less likely to make decisions with future market potential in mind. The UWL Repository was also conceived to help respond to national and funder mandates of which the most widely applied in the UK is the Research Excellence Framework (REF).
7. Long-term preservation
Institutional repositories often employ librarians who specialize in ensuring long term archiving. As such, the preservation policies developed for institutional repositories,including the UWL Repository, typically enable items to be retained over an indefinite period and take reasonable efforts to ensure continued readability and accessibility. This is vital where ‘some publications in the repositories may not be published elsewhere. This is often the case with student theses and doctoral dissertations, as with report series, digitised material and open educational resources’ (Ball, 2010).The UWL Repository also regularly backs up its files according to current best practices and regulates withdrawal of records according to a stringent set of criteria (such as proven copyright violation, plagiarism or research that otherwise breaches the University’s code of conduct).
Academia.edu and ResearchGate on the other hand, are independent for-profit companies that could cease operating at any time. While Academia.edu disavows any duty to warn users if they shut down, ResearchGate places unreasonable demands on the user to be kept informed of changes to their terms of service:
Academia.edu “reserves the right, at its sole discretion, to discontinue or terminate the Site and Services and to terminate these Terms, at any time and without prior notice.”
ResearchGate “We reserve the right to modify the Service or to offer services different from those offered at the time of the User’s registration at any time. […] You are obliged to check your account regularly for a notice about changes to these Terms.”
8. Recognition of open access policies
The Research Excellence Framework (REF) 2021 Guidance on submissions (2019) sets out the criteria for open access compliance in order to help assess the types of research being produced by higher education institutions in the UK. One of the requirements states that the ‘output must have been deposited in an institutional repository, a repository service shared between multiple institutions, or a subject repository’. Since Academia.edu and ResearchGate are not institutional repositories, do not have a clear subject-disciplinary focus, and do not satisfy other funder requirements, embodied by pan-European funder initiatives such as Plan S (this stipulates the need for OpenAIRE compliance, quality metadata in interoperable format, continuous availability, etc.), they are widely considered to be unsuitable venues for open access impact evaluation (Hubbard, 2016).
Furthermore, REF guidance states that an ‘output must be deposited within the repository within a specific timeframe, determined by the date of acceptance’. Academic social networking sites such as Academia.edu and ResearchGate however provide no option to upload an accepted manuscript (also known as the post-print) as the article file type. Academia.edu for example, only supports ‘published works’ and non-descript ‘drafts’ for articles while ResearchGate similarly provides a binary choice between ‘published research’ or ‘preprints’ which have not yet been subject to peer review. In the case of both platforms, authors are limited to assigning just one date per record. These limitations and poor metadata standards make it exceptionally difficult to determine the point at which an article was accepted for publication, particularly as an article’s publication status changes over the course of its transition from first submission to final publication. This has clear implications for research and scholarly auditing processes which ultimately affect allocation of future funding to institutions.
What then may outwardly appear as sleek and minimalist upload interfaces that simplify the process of depositing for users, are services that are largely stripped of the checks and balances that would otherwise allow authors, creators, auditors and funders to navigate complex questions of ethics, licensing, ownership, provenance, time-stamping and compliance.
9. Dedicated support
COAR (2019) suggest that while large, centralized infrastructure and services such as Academia.edu and ResearchGate may be easier to market, ‘they cannot be as responsive to a diversity of needs and priorities across regions and domains. In addition, local services can engage with the local researchers to help ensure that their outputs are being described and deposited correctly’.
In this regard, the UWL Repository represents a support service for researchers and scholars based at the university as well as a vehicle for providing green open access.
The Repository website provides clear author guidance on how to deposit, through the availability of step-by-step guides and a video tutorial; details on relevant policies, copyright and flavours of open access; advice on how creators can responsibly promote their work for impact and a section on frequently asked questions.
In addition to this repository administrators manually review and enhance deposited records to monitor open access compliance, ensure integrity of research and scholarly outputs and check records against publisher terms for copyright and self-archiving.
This contrasts starkly with the disclaimers around liability and customer support which are featured heavily throughout Academia.edu and ResearchGate’s terms of service:
ResearchGate: Scope of the Service (2019)
‘We do not preview or review or filter such information, neither manually nor automatically. Therefore, we do not and cannot have current knowledge of possible infringements, inappropriate content, or violations of law caused by information that is uploaded by and/or stored upon the request of Members’.
Academia.edu: Disclaimers (2019)
‘THE SITE, SERVICES AND COLLECTIVE CONTENT ARE PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED. WITHOUT LIMITING THE FOREGOING, ACADEMIA.EDU EXPLICITLY DISCLAIMS ANY WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, QUIET ENJOYMENT OR NON-INFRINGEMENT, AND ANY WARRANTIES ARISING OUT OF COURSE OF DEALING OR USAGE OF TRADE. ACADEMIA.EDU MAKES NO WARRANTY THAT THE SITE, SERVICES OR COLLECTIVE CONTENT WILL MEET YOUR REQUIREMENTS OR BE AVAILABLE ON AN UNINTERRUPTED, SECURE, OR ERROR-FREE BASIS. ACADEMIA.EDU MAKES NO WARRANTY REGARDING THE QUALITY OF ANY PRODUCTS, SERVICES OR COLLECTIVE CONTENT PURCHASED OR OBTAINED THROUGH THE SITE OR SERVICES OR THE ACCURACY, TIMELINESS, TRUTHFULNESS, COMPLETENESS OR RELIABILITY OF ANY CONTENT OBTAINED THROUGH THE SITE OR SERVICES.
NO ADVICE OR INFORMATION, WHETHER ORAL OR WRITTEN, OBTAINED FROM ACADEMIA.EDU OR THROUGH THE SITE, SERVICES OR COLLECTIVE CONTENT, WILL CREATE ANY WARRANTY NOT EXPRESSLY MADE HEREIN’.
10. Standards
International registries:
The UWL Repository is registered with Directory of Open Access Repositories (OpenDOAR) which is the quality-assured global directory of academic open access repositories. It enables the identification, browsing and search for repositories, based on a range of features, such as location, software or type of material held.
Adherence to technical standards:
The UWL Repository ensures all metadata – the information about what’s in the repository – are interoperable and open by using an internationally-agreed set of technical standards. This common protocol to which it adheres is called the open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and is stewarded by OpenAIRE.
Persistent identifiers (PIDs):
The UWL Repository uses persistent identifiers (PIDs) such as ORCiDs and digitial object identifiers (DOIs) in an attempt to solve the problems of resource identification and long-term access to online digital materials. PIDs allow resources within the repository to be uniquely identified in a way that will not change if the resource is renamed or relocated, and will persist regardless of the protocol used to access it. This means that a resource can be reliably referenced for future access by humans and software.
Indexing and search engine optimisation (SEO) standards:
UWL Repository content is searchable via major search engines including Google Scholar and allows indexing with services such as CORE.
Compliance with copyright and licensing conditions:
SHERPA RoMEO is an online resource which aggregates and analyses publisher open access policies from around the world and provides summaries of self-archiving permissions and conditions of rights given to authors on a journal-by-journal basis. The UWL Repository and its users navigate this service to find out which version of their articles can be self-archived under what condition, ensuring all outputs are licensed appropriately and archived responsibly.
Open source:
The open source software upon which the UWL Repository is based (EPrints) leverages the care and knowledge of the community of developers, librarians and users that feed into its progress.
Jordan, K., 2015. Exploring the ResearchGate score as an academic metric: reflections and implications for practice.
Makula, A. (2017). “Is it like academia.edu?”: Faculty perceptions and usage of academic social networking sites and implications for librarians and institutional repositories. Journal of New Librarianship. 2 (1)
Murray, M. (2014). Analysis of a Scholarly Social Networking Site: The Case of the Dormant User. SAIS 2014 Proceedings. 24. Available: https://aisel.aisnet.org/sais2014/24. Last accessed 02/10/2019
In the last of this week’s series of brief posts to celebrate #openaccessweek2018, we consider how you can make open research practice a part of your praxis as active researchers.
So, now we know what the routes to open access are, where can we go to publish openly?
As open scholarship is part of your research work lifecycle, open access doesn’t simply start after you have written the first draft of your manuscript. Open scholarship is something that needs to be baked throughout the entire research process, and not just considered at the point of submission for publication.
Preprints are the version of scholarly outputs that exist prior to their submission to a journal or editor for peer review. Sharing preprints mean that you can benefit from the input of others prior to peer review, helping to expedite the process of revision, and opening the doors to wider collaboration.
Many preprints servers exist in a wide range of disciplines, but the first and most established in the area of physics and mathematics is indisputably arXiv. However, this has spawned equivalents such as bioArxiv and socArxiv, that operate in similar models, but with a disciplinary limitation that makes sense for researchers in these disparate areas.
Perhaps the best starting place for helping ensure that you select the right place to submit your article is https://thinkchecksubmit.org. This website runs one through a series of questions to help you to ensure that the journal you are considering submitting your work to is a reputable title.
One of the resources it will recommend considering is the Directory of Open Access Journals (DOAJ). DOAJ works as a ‘whitelisting’ service that validates the credentials of a publisher, but it also is a directory of journals which you can interrogate to find reputable open access journals in your disciplinary area!
Of course, for your green open access needs, the UWL Repository is something that the UWL Publications Policy requires you to use, but there are also hundreds of subject repositories that you may also wish to deposit your accepted manuscript in to maximise its visibility in a range of indexes and locations.
But what about the research data that underpins your journal articles?
Well, we do not currently have an institutional data repository. However, there are other services that you can make use of. For instance Zenodo is an open source service developed and operated as part of the CERN project. Zenodo allows you to deposits data sets of up to 50gb each for free, and these can be open or closed. Similarly, figshare is a gratis service offering open and closed deposit spaces that come with a free DOI that can be provided to publishers to link the dataset to the paper.
As ever, we are here to help, and if you need to get in touch, you can always drop us an email. In the first instance why not contact our Research Support Manager, Kevin Sanders, via kevin.sanders@uwl.ac.uk 🙂
In today’s post we’re going to focus on our collections of theses, as part #openaccessweek2018 #ThesisThursday!
One of the major positive aspects of the UWL Repository that Library Services are keen to promote is one far removed for the world of compliance and interpretation of open access policies and mandates.
Such mandates predominantly fall upon research outputs from academic staff that are employed within an institution or organisation, and are often more established within the academe.
However, some of the most exciting research undertaken by universities is the work of PhD candidates. Their theses are the culmination of extended and highly reviewed research, practice, application, and production.
The UWL Repository helps to showcase deposited theses and research dissertations, making them discoverable and accessible to a wide range of publics. The digital availability of theses has seen their value jump dramatically compared their scant use as reference only, physical materials, that traditionally occupy dusty shelves across the world.
But the UWL Repository saw an impressive 3’477 (IRUS-UK) theses downloads in 2016, which climbed almost threefold through 2017’s staggering 9’123 (IRUS-UK) downloads. 2018 has already seen another strong performance with well in excess of 5’000 (IRUS-UK) downloads up to September alone!
But I am cautious around framing the benefits of making theses available through open access in terms of big numbers. These downloads demonstrate how this cutting edge research is made accessible to eager publics, and that the work is in high demand.
The analogue print form of the thesis, traditionally stored in the stacks of academic libraries and almost invariably as a reference only resource, rarely yielded reference, but now the digital version allows greater freedom to users, and the discoverability provided through the UWL Repsoitory is key to uniting the reader with the research.
This digital evolution for theses has created a ‘crack’ which early career researchers can then develop by building their profile and strengthening stronger links with researchers and practitioners that are active within and across their given discipline(s).
If PhD candidates link their repository account to their ORCID account, that will also be associated at metadata level. Now that we have fully integrated UWL Repository with ORCID, they can export their record to their ORCID profile with the click of a button to save. In turn, this machine-to-machine sharing of data helps to retain greater accuracy and continuity across different systems in the scholarly communications landscape.
As the University seeks to develop its culture of research, our PhD candidate numbers are set to dramatically increase, and we look forward to serving all of our past, current and future candidates by showcasing their theses- and other outputs- in the UWL Repository.
For today’s brief post, we are going to consider the nature of open access. In its current form, it is easy to see open access and openness as a bureaucracy that researchers must participate in in order to appease funders and auditors. However, this negates the histories of open access, which might help us to see the possibilities that open access can open for researchers and users alike.
However, open access is somewhat of a nebulous concept, with “a number of different lineages, from the formalising of pre-existing preprint cultures via subject repositories and the emergence of institutional repositories, to the free culture and open-source software movements” (Moore, 2017).
As Moore goes on to note, these “separate lineages do not make for a consistent set of values associated with OA, especially against the backdrop of unique disciplinary publishing cultures” (2017), and as such, conceiving open access as a single and unified thing is perhaps somewhat of a falsehood.
Instead, Moore posits that open access can “be seen as a process of understanding, engaging and experimenting with the ways in which research is presented and disseminated [and therefore be] considered and fostered as a community-led initiative”. This conception of open access certainly allows for far more in the way of flexibility and experimentation by and for the broad and disparate communities producing and using (open access) knowledge, information, and data.
However, with the emergence of more policies in the area, it is clear that funders are keen to maintain a certain trajectory with regards to achieving their desires for open access to scholarly outputs. However, even working within these confines, this does not per se mean that we cannot expand openness to outputs.
For instance, it seems more than possible for creative works to gain a greater platform through the mechanics and infrastructure offered by our pre-existing open access architectures.
Video, sound, music, and scores could all be better represented in the open scholarly indexes through this, presenting themselves alongside textual information which often retains a disproportionate reification through conservative and orthodox approaches to scholarly communications. In turn the normalisation of non-textual media being present within the scholarly indexes might foster more experimental approaches towards the presentation of scholarship and research outputs.
If information and open access is a process, we do not have to hold on to techniques and strategies that relate to analogue forms of communicating where digital media inherently offers alternatives.
Let’s enjoy that and experiment with new media to help achieve better and more diverse forms of impact.
References
Moore, S. (2017). A genealogy of open access: negotiations between openness and access to research‘. Revue Française en sciences de l’information et de la communication, (11)2: [Accessed 24/10/2018] https://journals.openedition.org/rfsic/3220
Welcome to day two of our short blog posts that neatly align with #OAWeek! Yesterday, we looked at why open scholarship and open research- an essential starting point from which one can learn about what openness offers researchers, institutions, and wider publics! Today we are going to look at the routes to achieving open access, and considering some of the wider concerns in this area, especially with regards the importance for foundation of systems for producing and distributing knowledge also being based in an open context.
As we all are well aware, there are two routes to achieving open access: Gold open access and Green open access.
The Gold route means publishing your work as open access, usually with an appropriate licence, such as a Creative Commons licence like CC BY.
The Green route involved depositing a copy of the author’s accepted manuscript into an applicable institutional or subject repository. This version of the paper should be intellectually the same as the published version of record, but the (c) has not been transferred to a publisher at this point.
Since the Finch Report (2012), article processing charges (APCs) have become a common way for legacy publishers to flip the business models over to supporting open access whilst allowing their revenues to maintain (or even increase if the journal is a traditional subscription journal with the opportunity publish an article as gold open access- this is known as a hybrid journal, and often leads to double-dipping as universities pay to access and publish content).
While APCs are a completely legitimate business model for covering the costs of publication, the Finch Report’s desire to create a market for APCs that would lead to competition and thus price reduction was perhaps naive as it failed to adequately account for the prestige factor that journal titles have accrued over time. This has led to a dysfunctional market that commodifies scholarship and research information objects in the context of publication, entrenching inequities and disparities between researchers and HEIs that lack the capital to pay for high APCs in the most prestigious legacy titles.
However, APCs are by no means the only business model to create sustainable open access publications. Many scholar-led open access publications exist that require no author-side fees. In fact, as Suber has consistently noted, over 70% of open access titles have no fees associated with publication! Many make use of free and open source publishing software such as Public Knowledge Project’s Open Journals System or the Open Library of Humanities’ Janeway to help reduce licensing costs on software.
Indeed. The Open Library of Humanities have a very novel Gold open access business model with no author side fees. Instead, they obtain partnership subsidies from libraries to cover their operational costs and thus publish high quality open access material with no author-side fees at all.
At the University, we formally support Green open access through the UWL Repository, which is currently based of the free and open source EPrints software.
All one has to do as a researcher is deposit your accepted manuscript as close to the point of acceptance. Journals may impose embargo periods, during which the accepted a manuscript will not be accessible, so if you want to choose a title that will allow for access from the point of acceptance or publication (i.e. zero embargo), or one with a very minimal embargo to maximise its exposure with currency, you can use SHERPA/RoMEO to check on a publication’s support for depositing in repositories.
The significance around open source software for open access to scholarship is not only philosophical, but also very practical. Proprietary systems do exist, and offer enticing systems that cater to the needs of institutions. However, the proprietary nature of such systems is in direct contrast to the nature of open scholarship. The systems may not provide exportable data for future migrations, effectively locking customers to vendors. Other issues relate to how the suppliers of proprietary systems make use of user data, which is often opaque, but in a post-Snowden, post-Cambridge Analytica world, this is a very real concern for those of us working with personally identifiable information and data.
References
Finch, J. et al. (2012). Accessibility, sustainability, excellence: how to expand access to research publications: Report of the working group on expanding access to published research findings [Last accessed 18/10/2018] https://www.acu.ac.uk/research-information-network/finch-report-final
In this first of our short daily blog posts for Open Access Week 2018 (join in the conversations on social media using #OAWeek), we address why researchers should be seriously considering how open scholarship in its broadest sense can bring them advantages over traditional forms of scholarly communications.
April saw the implementation of the Decisions of Staff Outputs’ revised policy on open access on REF eligibility. Any journal article or conference proceeding with ISSN accepted for publication after 01/04/2018 must be deposited into the repository as close to the point acceptance as possible, and no more than three months after acceptance.
With this in mind, it was pleasing, therefore to see a congruent rate of deposit in April with 63 items deposited, compared to March (54), February (59), and January (56).
However, there are other conditions that must be met for REF eligibility according the policy for open access, which has been in place since 01/04/2016. Of particular note is the maximum embargo periods for different REF panels. For UoAs that fall under panels A and B, the embargo period cannot exceed 12 months, and for UoAs under Panels C and D, the embargo cannot exceed 24 months. For more details, please see out REF2021 FAQ
Elsevier have been particularly canny in this regard, having not set a blanket policy to accommodate author needs for REF, effectively strong-arming authors into gold open access for compliance with RCUK demands, too. As such, UoA 4 may need to pay particularly close attention to the embargo periods. We would strongly recommend using Sherpa/RoMEO for general guidance, and for publisher specific enquiries, please feel free to get in touch. (Elsevier’s current title embargoes list for UK-based authors as available here).
On the 16th of May, we are running a session on gold and free open access as part of the Research and Enterprise Office’s Brown Bag Lunch series. We’ll be talking about what open access is, why it has emerged, how it works, how to make your work available through various open access routes, and what this can do for authors and the University at large. Come to the Savoy Suite from 13:00-14:00, and don’t forget your lunch!
Much like The Beast from The East, March came and March went, but certainly not without notice for the UWL Repository.
Indeed, the last month has seen the UWL Repository hit several milestones. Firstly, we now have over 3’000 outputs recorded in the repository. This corpus of deposits has also yielded over 70’000 downloads!
The number of outputs discoverable and accessible from the repository is expected to rise rapidly following with the REF eligibility mandate for open access to journal articles and conference proceedings with ISSNs shifting. These item types must now be deposited to the repository within three months of acceptance in order to be eligible for the REF.
Given the increasing requirement to use the repository at the institutional and If you need any support or assistance with queries relating to your use of the repository, please do not hesitate to get in touch!
Louise Penn, Resource and Technology Manager, and Kevin Sanders, Research Support Manager, recently gave a well-attended session on ‘The REF, Stern, and You’ as part of the Brown Bag series of sessions organised by the Research and Enterprise Office. This allowed a lot of information to be shared, and also was a convenient place for a range of interrelated issues to be raised.
Louise and Kevin are running another session in this series on Green and Gold Open Access, and we would strongly encourage to take the opportunity to speak to them about the various nuances around different routes to achieving openness with regards to your scholarly outputs. Indeed, with the University’s New Vistas title looking to migrate to a formal OA publishing platform and licensing model later in the year, it might be a great opportunity to learn more about what this all means.
Westminster Higher Education Forum Keynote Seminar: The next steps for delivering open access – implementation, expansion and international trends
This event is important as it foreshadowed UKRI and Research England’s official operations, providing some insights into their initial focus on open access and openness in scholarly pursuits.
The event covered some familiar ground, but Sir Mark Walport gave a rapid overview of the current and possible future OA policy landscape just before UKRI came into fruition, noting:
UKRI is committed to Open Research, going beyond open access to scholarly outputs, and including open data, open metadata, open metrics, and (possibly) open peer review.
The five-year transition targets envisioned by Finch have not been met. The relative value for money from the investment in gold open access needs to be assessed, and UKRI’s timely development makes them well placed to make this assessment.
There are two areas where the UKRI could make a positive intervention: with the UK-SCL and DORA (https://sfdora.org). However, Sir Walport was not explicit about what these interventions might be.
UKRI is planning a review of OA policy over the next year. It will be an ‘internal’ review, but they will seek input from external stakeholders. It will cover:
have the existing policies worked?
how do they compare with other countries?
what should any future policy be?
On the issue of future policy, it was noted that it:
has to be sustainable and provide value for money
will cover all of the research councils, in a unified policy
will need to address double-dipping.
Should take note of the fact that much of the current funding goes into APCs for hybrid. Sir Walport raised the possibility of a ban on spending from the block grant for certain types of hybrids operations, although UKRI would ‘need to think about this carefully’.
A key take-away was that the community needs to start thinking carefully about what we would want from a new policy – especially around the issue of hybrids. It sounds as if the review is imminent.
Here is a re-blog of a personal blog post written by our Research Support Manager, Kevin Sanders.
Growing bulbs of intellectual freedom from academic libraries
As many of us are increasingly aware, data pertaining to our online behaviour- when and where we have been, what we did whilst occupying that space, etc.- have become increasingly valuable to a range of stakeholders and bad actors, including unethical hackers, commercial organisations, and the state. The weaknesses inherent across various web infrastructures, their deployment, and their ubiquitous, multipurpose uses are routinely exploited to capture the private data and information of individuals and entire communities.
For many librarians, this technological and cultural problem has been increasingly acknowledged as part of a wider political concern that is directly relevant to our professional requirement to protect the right to intellectual privacy (Fister, 2015; Smith, 2018).
Through both my professional and voluntary labour with the Library Freedom Project and the Radical Librarians Collective, I have been trying to directly offer support for individuals in their attempt to protect their privacy through their behaviours and the digital tools they choose to make use of. However, consistently weaving intellectual privacy throughout my professional praxis is a significant challenge.
Peeling back the layers of libraries and the scholarly commons
I am currently employed as the Research Support Manager for Library Services at the University of West London (UWL). A significant aspect of my role is to manage and administrate the UWL Repository, which is the institution’s repository of research outputs. The repository makes these outputs discoverable and accessible through what is known as green open access.
The collection, storage, management, and sharing of information demonstrated in the administration of a repository are all core elements of library work. However, this specific aspect of library work directly contributes towards the development and maintenance of the scholarly commons as an accessible body of work that “admit[s] the curious, rather than [only] the orthodox, to the alchemist’s vault” (Illich, 1973), and to allow people to re-use the research for their own purposes.
In all areas of library work, ensuring that the personal data and information of our user communities is stored securely is very important for the preservation of intellectual privacy. However, in the contemporary environment, libraries’ digital connections to external sources and services can make this challenging. Libraries are reliant on services that are served externally, and as such libraries lack the ability to control how these services share data required for the use of these services.
As the University have control over the repository through an agreement with a hosting service, it has been easy enough to enable some security enhancements. As such, from January 2018, the UWL Repository has been wrapped in HTTPS to respect our user communities’ information security by ensuring that all connections to it are encrypted.
Unfortunately, the scholarly commons is only as accessible as it is permitted to be on the clear-net, as there are many powerful stakeholders that have the ability to suppress access and thus censor scholars and other publics from accessing the published results of academic research and scholarship.
Onions don’t grow on trees; environmental ethics and the scholarly commons
Some popular online services and networks for scholars, such as Sci-Hub, ResearchGate, academia.edu, also offer users the option to share their scholarly and research outputs gratis. The latter two are capital venture funded, commercial services. Part of their business operations include providing data around research that can, it is claimed, offer insights into its ‘impact’. However, these services do not take responsibility for the frequent breaches of licences that help to calcify the commodification of scholarly knowledge (Lawson et al., 2015,). Many of these services also have vested interests in the data stored and created through the use of their services.
For the scholarly commons, publishing via open access (through both gold open access publishers and via institutional and subject repositories) and making use of appropriate Creative Commons licences is a significantly more effective and ethical way to share and access research and scholarly outputs. Institutional repositories are commonly sustained by institutional funding (i.e. they serve not-for-profit functions), for instance, and they also commonly run on free (libre) and open source software such as EPrintssoftware, which is licensed under GPL v3.0.
Here, we can see that libraries actively support a libre approach to free, online access to scholarly information.
Layering up for intellectual privacy, access, and the scholarly commons
As referred to above, various fields of informational labour hold a broad consensus view around users’ right and need for intellectual privacy (Richards, 2015). In this context, ensuring that the research and scholarly outputs are accessible in ways that allow users to retain their privacy seems essential.
As such, I have made the UWL Repository accessible from within the Tor network as an onion service.
I briefly consulted Library Services’ director, Andrew Preater, prior to undertaking this work, but I was able to make use of Enterprise Onion Toolkit (EOTK) to create a proxy of the repository without requiring root access to the webserver of the clear-net site, and without having to make copies of the files held on that server. As a proof-of-concept, it is now accessible via https://6dtdxvvrug3v6g6d.onion, but may be moved to a more permanent .onion address in the future, subject to institutional support. (Please note that an exception has to be granted to access the onion service due to some of the complexities of HTTPS over onion services. This is something that I would hope to resolve with institutional support. Please see Murray’s post for further details).
This provision allows global access to the UWL Repository and its accessible content in a form that allows users to protect their right to intellectual privacy; neither their ISP nor UWL, as a service provider, will be able to identify their personal use of UWL Repository when using https://6dtdxvvrug3v6g6d.onion/.
Having repositories available as onion services is of significant benefit for those accessing the material from, for instance, oppressive geopolitical contexts. Onion services offer not only enhanced privacy for users, but also help to circumvent censorship. Some governments and regimes routinely deny access to clear-net websites deemed obscene or a threat to national security. Providing an onion service of the repository not only protects those that may suffer enhanced digital surveillance for challenging social constructs or social relations (which can have a severely chilling effect on intellectual freedom), but also on entire geographical areas that are locked out of accessing publicly accessible content on the clear-net.
The expansion of intellectual privacy for the scholarly commons is bringing tears to my eyes
Although this is a small step for the scholarly commons, it is an important one. In our politically fragile world, marginalised communities often suffer disproportionate risks, and taking this simple step helps to reinstate somesafety into this digital space (Barron et al., 2017). As Ganghadharan (2012) notes, “[u]ntil policy–makers begin a frank discussion of how to account for benefits and harms of experiencing online worlds and to confront the need to protect collective and individual privacy online, oppressive practices will continue”.
I hope that other library and information workers, repository administrators, open access publishers, and their associated indexing services will take inspiration from the step that I have taken and help us to lead a collective charge that places intellectual privacy at the centre of both the scholarly commons and digital library services.
Acknowledgements:
I would like to thank Murray Royston-Ward and Simon Barron for their technical support (if you do not have access to a server, Murray has written a guide to trialling a Tor mirror of services via Google’s Cloud Engine), Alec Muffett for his development of EOTK, Alison Macrina and the Library Freedom Project for their advocacy of digital rights within libraries, the Radical Librarians Collective for providing spaces to support my professional development and practical skills, and to all those involved in the Tor Project that support and provide tools that allow us to make good on our right to digital privacy.
Fister, B. (2015). Big Data or Big Brother? Data, ethics, and academic libraries. Library Issues: Briefings for Faculty and Administrators. [Retrieved from: https://barberafister.net/LIbigdata.pdf]
Gangadharan, S. P. (2012). Digital inclusion and data profiling. First Monday, 17(5)
Lawson, S., Sanders, K., and Smith, L. (2015). Commodification of the information profession: A critique of higher education under neoliberalism. Journal of Librarianship and Scholarly Communication, 3 (1). [Retrieved from: http://dx.doi.org/10.7710/2162-3309.1182]
Richards, N. (2015). Intellectual privacy: Rethinking civil liberties in the digital age. Oxford University Press, USA